The Problem Nobody Is Talking About: AI Agents Have No Backbone
Every benchmark comparing Claude Code, Codex, Cursor, and Opencode measures the same narrow metric: output quality on a discrete task. Does the generated function compile? Does the diff look clean? These are reasonable questions, but they ignore the three capabilities that determine whether an AI coding tool actually works inside a real engineering organization — memory, learning, and security persistence across sessions.
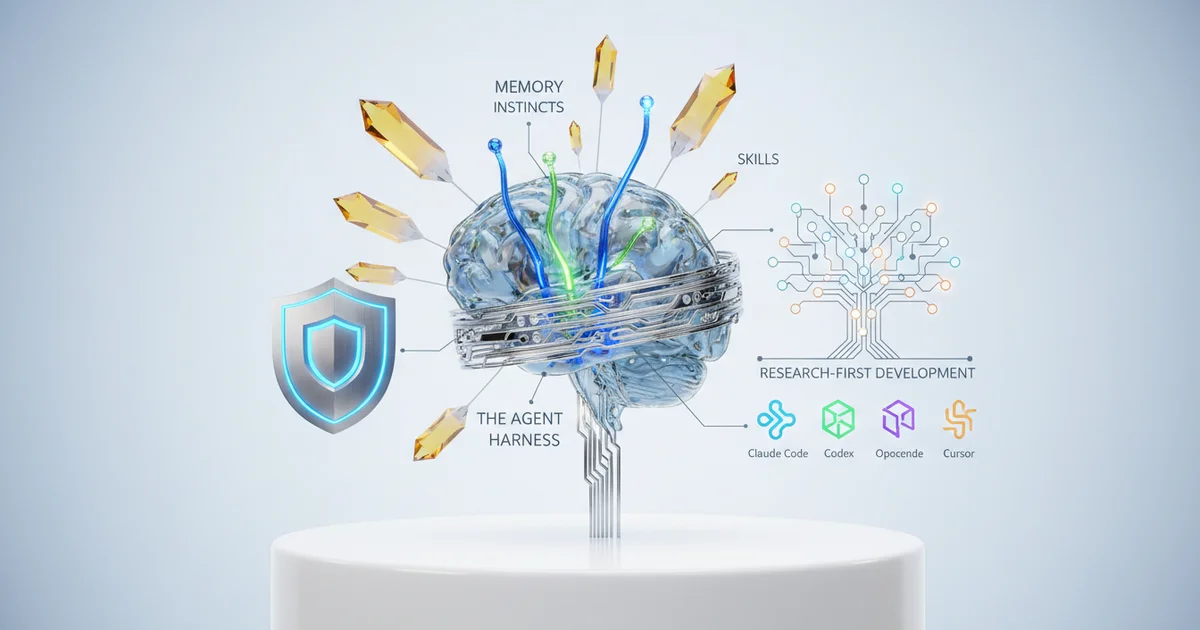
The gap becomes painful the moment a developer runs more than one agent. Each tool arrives with its own context window, its own configuration surface, and zero knowledge of what happened in the session before. Institutional knowledge — the coding conventions your team spent months establishing, the security patterns baked into your CLAUDE.md file, the debugging heuristics that saved a production incident — evaporates the moment you switch tools or start a new session. Developers are not just evaluating agents; they are rebuilding their working environment from scratch, repeatedly.
This is the core argument for what engineers are starting to call an agent harness layer. The concept reframes tools like Claude Code not as finished products but as runtimes — execution environments that need an external substrate to handle memory, observability, and policy enforcement at scale. Affaan Mustafa’s everything-claude-code project, which has accumulated over 61,000 GitHub stars, points toward what this substrate looks like in practice: a structured ecosystem of agents, skills, commands, and hooks that sit above any single model and give it persistent context and composable behavior.
Without that layer, the AI coding market produces a collection of powerful but stateless tools. With it, individual agents become interchangeable runtimes inside a workflow that remembers, enforces rules, and compounds knowledge over time. The teams building toward this architecture are not chasing the best autocomplete. They are solving the infrastructure problem that makes autocomplete matter.
What ‘everything-claude-code’ Actually Built — And Why It Spread So Fast
Affaan Mustafa built everything-claude-code as a single, opinionated hub for developers trying to do serious work with Claude Code — and 61,000 GitHub stars later, it stands as the most-starred resource dedicated specifically to the tool. That number isn’t just a vanity metric. It signals a gap that Anthropic’s own documentation wasn’t filling: developers wanted battle-tested patterns, not reference pages.
The project ships a concrete ecosystem rather than abstract advice. Nine agents, eleven skills, eleven commands, and ten hooks give developers building blocks they can drop into real workflows immediately. Mustafa also won the Anthropic x Forum Ventures hackathon building with Claude Code, which means the framework reflects hands-on experience with the tool’s actual constraints, not theoretical best practices assembled from the outside.
The growth model explains a lot of the spread. Everything-claude-code runs on a free tier sustained by GitHub Sponsors rather than a paywall, which eliminates the friction that kills adoption for most developer tools. The logic mirrors how Linux and Homebrew became ubiquitous infrastructure — when the barrier to entry is zero, adoption compounds fast. Sponsors fund premium extensions and get priority support and roadmap votes, but the core resource stays accessible to everyone. That structure lets Mustafa keep building — a Skill Creator GitHub App that generates Claude Code skills directly from a user’s own repository is already in development — without locking the community out.
What the star count ultimately reflects is a market reality the AI coding tool space hasn’t fully absorbed: raw AI capability ships faster than the frameworks needed to harness it. Vendors release models and APIs. The hard work of turning those into reliable, composable agent behavior falls to the developer community. Everything-claude-code filled that vacuum for Claude Code specifically, and its traction confirms that developers will rally behind opinionated, community-built infrastructure when the official alternatives leave too many questions unanswered.
Skills, Instincts, Memory: Reframing How We Think About Agent Intelligence
Most discussions about AI coding tools collapse into a single question: which model writes better code? That framing misses what practitioners building serious agent infrastructure are actually solving for.
The everything-claude-code project, which has accumulated over 61,000 GitHub stars, draws a sharp distinction between three layers of agent intelligence: skills, instincts, and memory. Skills are discrete, teachable capabilities — specific behaviors an agent can learn and execute on demand. Instincts are baked-in behavioral defaults, the baseline dispositions an agent brings to any task before any instruction is given. Memory is persistent context that carries forward across tasks, preventing agents from starting from zero every session. Vendor tooling has not standardized this taxonomy, which means most development teams are building on top of categories they haven’t formally named, let alone engineered deliberately.
The Skill Creator, a GitHub App in active development under the everything-claude-code roadmap, generates reusable agent capabilities directly from a repository. The design logic points toward something larger: a future where development teams compose and share AI behaviors the way they share open-source libraries. The project already ships with nine agents, eleven skills, eleven commands, and ten hooks — a working demonstration that agent behavior is modular, not monolithic.
That modularity reframes the competitive landscape. A team that invests in well-engineered skills, tuned instincts, and persistent memory builds an advantage that doesn’t evaporate the moment a rival model releases a new version. Workflow architecture compounds. Model capability, by contrast, is a commodity that every competitor can access on the same day a new release drops.
The shift from “which model is smarter” to “which workflow is better engineered” is not a philosophical point — it is a strategic one. Teams that treat agent intelligence as a designed system rather than a purchased feature are building something defensible. Teams that don’t are renting capability they don’t control.
Security and Research-First Development: The Missing Layer in AI Coding Hype
The loudest conversations around AI coding tools fixate on benchmark scores and lines-of-code-per-hour metrics. Almost none of them ask how an agent handles a leaked API key in a prompt, what happens when it receives malicious instructions through an untrusted input, or how it manages permissions when operating autonomously across a codebase. That silence is a structural problem, not an oversight.
Most AI tooling companies treat security as a layer added after product-market fit is confirmed. The pattern is familiar: ship fast, gather users, patch vulnerabilities when they become embarrassing. This approach works for consumer apps. It fails for agents that execute code, read file systems, and make authenticated API calls on behalf of developers.
A research-first development philosophy inverts that sequence. Features get stress-tested against documented agent failure modes — prompt injection, credential exposure, privilege escalation through tool chaining — before they reach users, not after a security researcher files a public disclosure. The everything-claude-code project, which has accumulated over 61,000 GitHub stars and encompasses nine agents, eleven skills, and ten hooks, operates under this model. Validation against real-world failure scenarios is built into the shipping process rather than bolted on as an afterthought.
The distinction matters at scale. A single misconfigured hook or an agent that passes secrets into a subprocess without sanitization can compromise an entire development environment. When the underlying operating layer for AI agents gets this wrong, every tool built on top of it inherits the vulnerability. When it gets it right from the start, that security posture compounds upward through the entire stack.
Speed benchmarks will keep dominating headlines because they are easy to measure and satisfying to publish. But the teams building durable infrastructure for AI-assisted development understand that an agent operating layer earns trust through what it refuses to do as much as through what it can do.
Cross-Platform Ambition: Why Supporting Cursor, Codex, and Opencode Changes the Stakes
Supporting a single AI coding tool builds a plugin. Supporting all of them builds a platform — and that distinction determines who holds power in the next phase of software development.
Projects like everything-claude-code, which has accumulated over 61,000 GitHub stars, demonstrate what happens when a resource targets the ecosystem rather than a single runtime. By designing a harness layer to work across Claude Code, OpenAI’s Codex, and Cursor simultaneously, a maintainer stops competing for users and starts competing for mindshare among developers regardless of which tool they run. That cross-platform commitment transforms the project from a vendor-specific convenience into infrastructure — something teams depend on before they even choose their primary agent.
The strategic upside is compounding. When adoption spreads across multiple runtimes, the harness layer effectively writes the norms: how agents receive instructions, how skills get structured, how hooks fire across autonomous workflows. Developers on Cursor and developers on Codex start following the same conventions not because a company issued a mandate, but because the shared tooling enforces consistency by default. The maintainer gains outsized influence over how agentic coding patterns develop industry-wide — a position no single-vendor plugin can reach.
This dynamic has a clear historical precedent. ESLint and Prettier did not conquer JavaScript development because any single company deployed them at scale. They became unavoidable because the community converged on them independently, project by project, until skipping them required active justification. A cross-runtime agent harness that reaches critical mass follows the same adoption curve. Once enough teams wire their CI pipelines, onboarding flows, and internal skill libraries around a common layer, the switching cost becomes prohibitive — not through lock-in, but through ubiquity.
The race to occupy that position is happening now, while agentic coding norms are still forming. Whoever establishes the de facto standard for how agents operate across runtimes will shape what “good” autonomous development looks like for years.
The Sponsorship Model as a Sustainability Signal for Open AI Infrastructure
Affaan Mustafa’s GitHub Sponsors page for everything-claude-code reveals something more structurally interesting than a typical donation button. The tiered model gives Pro+ sponsors direct votes on the product roadmap — a lightweight governance mechanism that neither pure open-source projects nor venture-backed startups typically offer. Open-source projects often lack formal input structures beyond whoever shouts loudest in GitHub issues. VC-backed tools answer to cap tables. This model answers to paying users who have a documented stake in what gets built next.
That distinction matters as AI developer tooling moves from novelty to infrastructure. The sponsorship structure funds three things simultaneously: faster development, a free tier that stays free, and priority support for sponsors. That last point is critical. Priority support creates a viable B2B-adjacent revenue stream without requiring a separate enterprise product or a sales team. Small teams and individual developers can fund the resource that over 61,000 GitHub users depend on, without Mustafa taking outside capital that would realign his incentives away from the community.
The traditional open-source funding crisis — where widely-used projects like OpenSSL or Log4j ran on volunteer labor until catastrophic vulnerabilities exposed the fragility — played out because no sustainable middle path existed between “corporate ownership” and “hope people donate.” The everything-claude-code model tests whether community-driven feature prioritization plus tiered access can close that gap specifically for AI tooling.
The political stakes here will sharpen fast. Foundational AI developer infrastructure — the layer that defines how agents are configured, how skills are shared, how hooks and commands propagate across codebases — shapes what developers can build and how they think about building it. Who funds that layer determines who steers it. In traditional open-source, that question took decades to become urgent. In AI tooling, the consolidation is happening in years. A sponsorship model that keeps roadmap control distributed among active users rather than concentrated in a single corporate backer is not just a funding strategy — it’s a governance argument about who should own the scaffolding of AI development itself.



